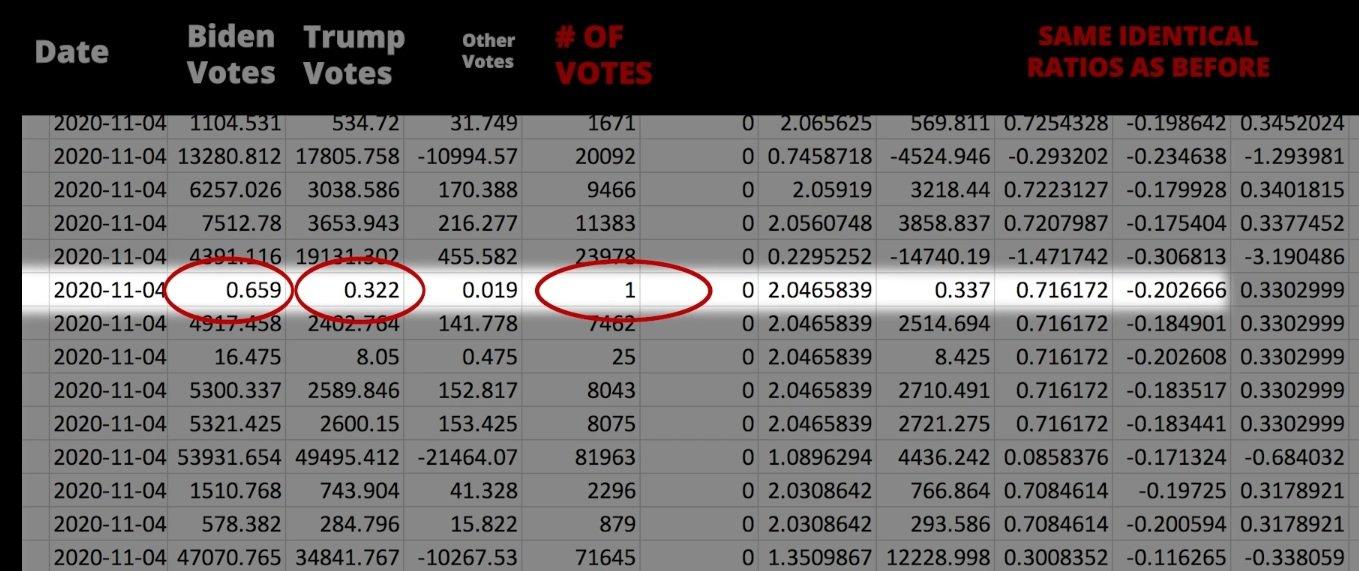
I am in complete agreement with your statement. What I am saying is, the data set that was used in this persons analysis (and MOST of the others that talk about "fractional data") are using the NYT scrap data set as their reference are not realizing THEY CREATED THE DECIMAL WHEN THEY DID THEIR CALCULATION.
The NYT .json scrap data was an incomplete data set. The NYT got their information from the Dominion (et al) servers, then when they got their NEXT piece of information, the previous piece got STORED in their .json database as a smaller amount of information (as I described above). This data had much less precision than the original.
I know its confusing. Many people succumbed to the exact same error, even good analysts. Even I did for a day or so, before I realized my mistake, and I've been working with large numerical data sets like this for twenty years.
I promise you: anyone who is getting decimals from the NYT data set is not "getting them" but calculating them themselves. The original (Edison) data set does not contain them.
That doesn't mean there are no places where there might be partial votes. The fact that you can calculate fractional votes in the Dominion machines themselves is a completely separate issue (e.g. we have seen real evidence that you can select a Biden vote to be worth 1.2 votes).
I don't know how the Dominion machines STORE those partial votes, but I do know the Dominion machines are not REPORTING those fractions, if they are stored that way at all (they probably are).

{kind=link}
I'm not buying it. There is no reason to ever have decimals as part of your calculations of votes. PERIOD. Just my opinion take it or leave it.
I am in complete agreement with your statement. What I am saying is, the data set that was used in this persons analysis (and MOST of the others that talk about "fractional data") are using the NYT scrap data set as their reference are not realizing THEY CREATED THE DECIMAL WHEN THEY DID THEIR CALCULATION.
The NYT .json scrap data was an incomplete data set. The NYT got their information from the Dominion (et al) servers, then when they got their NEXT piece of information, the previous piece got STORED in their .json database as a smaller amount of information (as I described above). This data had much less precision than the original.
I know its confusing. Many people succumbed to the exact same error, even good analysts. Even I did for a day or so, before I realized my mistake, and I've been working with large numerical data sets like this for twenty years.
I promise you: anyone who is getting decimals from the NYT data set is not "getting them" but calculating them themselves. The original (Edison) data set does not contain them.
That doesn't mean there are no places where there might be partial votes. The fact that you can calculate fractional votes in the Dominion machines themselves is a completely separate issue (e.g. we have seen real evidence that you can select a Biden vote to be worth 1.2 votes).
I don't know how the Dominion machines STORE those partial votes, but I do know the Dominion machines are not REPORTING those fractions, if they are stored that way at all (they probably are).