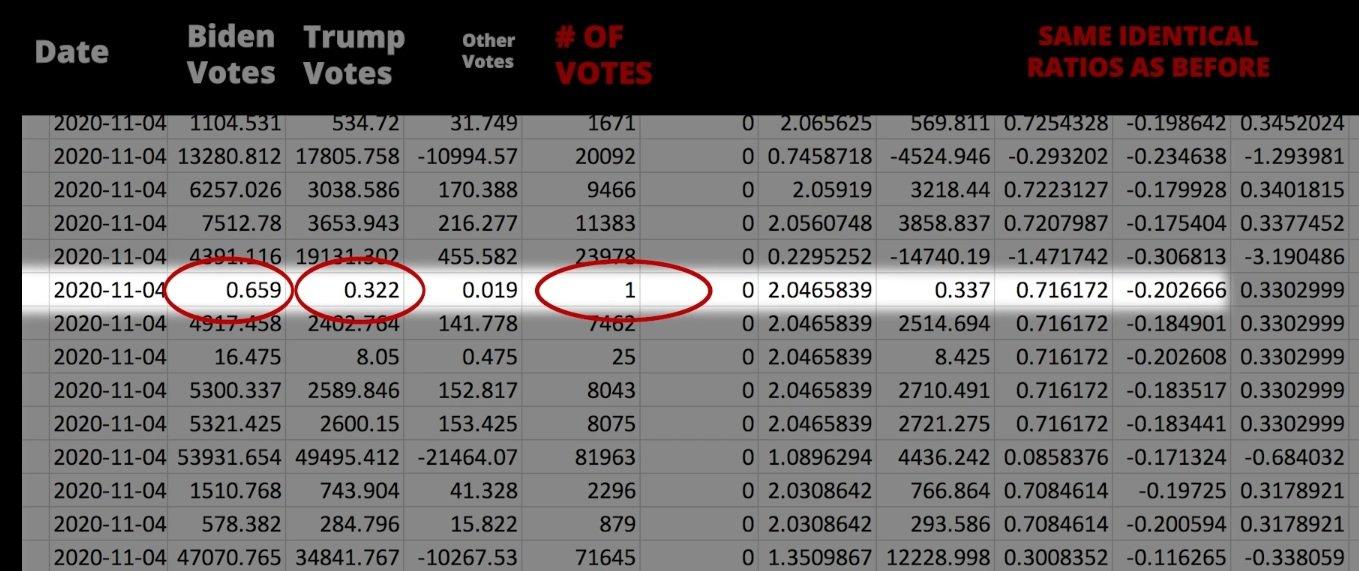
Assuming this is the data from the NYT election scrap data (which I am 99% sure it is) it is a decimal because of how it was calculated. In other words, this was an ANALYST error, not an error of the voting machines or reporting software. The scrap data was NOT the actual data. The actual data was from Edison. It was similar, but more accurate. The scrap data was only displayed to three decimal places. So same data, but less accurate. The scrap data was given in the format of:
Date, Total votes, .xxx, .yyy
where .xxx is the percent of of the total vote for Biden and .yyy is the percent of the total vote from Trump. Again, assuming this is the scrap data, the "# OF VOTES" column is (in this spreadsheet) calculated from the Total votes (current line minus previous lines of the Total votes column). It is because the data was only given to three decimal places (and because of how multiplication works) that all of the other columns are decimals. This has been an egregious oversight by many "analysts."
This error has given a lot of bad analyses. Even real mathematicians have made this mistake. Unfortunately mathematicians often don't work with actual data, and therein lies the problem. Don't get me wrong. There are PLENTY of REAL problems with the data that show it is not data from an election. I spent almost a month analyzing tons of election data and proved it was impossible, but this particular problem is analyst error, nothing more.
That's my point. The Edison data (the data that goes to the SOS of each state and is used to certify the elections) does not show that. The CALCULATION shows that.
Let me illustrate from a pretend entry from the NYT scrap data (again, the data set I believe this "analyst" used):
Date: 11/4/2020 12:00:00
Total Votes: 1,630,257
Biden Percent: .666
Trump Percent: .334
Other Percent: .000
Then, when you go to calculate the "Trump votes" and "Biden Votes" you get:
Biden Votes = 1,630,257 * 0.666 = 1,085,751.162
Trump Votes = 1.630,257 * 0.334 = 544,505.838
These calculations produce decimals (3 decimal point because that's how multiplication works). But that's not the real number being reported from the Dominion Servers to Edison (and presumably the SOS's).
The Edison data for such an entry would look something like:
Biden Vote: 1,086,129
Trump Vote: 544,128
These numbers not only don't have decimal places, but they aren't even the same number. The reason for this is one is reported (the Edison data) and the other is Calculated by multiplying a whole number (1,630,257) by a decimal accurate to the thousandths place (.666 e.g.).
The error value from such a calculation MUST be carried through or you get crappy analysis. In this case the real number from the Biden calculation is:
1,630,257 * 0.666 = 1,085,751.162 +/- 806.977
This means the REAL value for Biden falls somewhere between:
1,084,936.064 and 1,086,549.988 (which is confirmed in the Edison data).
This mistake was made by many people, not just the Jim Hoft, but he keeps running wild with it, making all kinds of false conclusions (like his "drop and roll" thing). Well, I shouldn't say his conclusions are all false, not all of them are. You don't need the increased precision from the Edison data to come to many of the conclusions, but a lot of his stuff is just plain wrong.
Again, the Edison data shows conclusively that it was NOT random samplings from a biased population (election data). In fact the Edison data shows it BETTER than the NYT .json scrap data.
I am in complete agreement with your statement. What I am saying is, the data set that was used in this persons analysis (and MOST of the others that talk about "fractional data") are using the NYT scrap data set as their reference are not realizing THEY CREATED THE DECIMAL WHEN THEY DID THEIR CALCULATION.
The NYT .json scrap data was an incomplete data set. The NYT got their information from the Dominion (et al) servers, then when they got their NEXT piece of information, the previous piece got STORED in their .json database as a smaller amount of information (as I described above). This data had much less precision than the original.
I know its confusing. Many people succumbed to the exact same error, even good analysts. Even I did for a day or so, before I realized my mistake, and I've been working with large numerical data sets like this for twenty years.
I promise you: anyone who is getting decimals from the NYT data set is not "getting them" but calculating them themselves. The original (Edison) data set does not contain them.
That doesn't mean there are no places where there might be partial votes. The fact that you can calculate fractional votes in the Dominion machines themselves is a completely separate issue (e.g. we have seen real evidence that you can select a Biden vote to be worth 1.2 votes).
I don't know how the Dominion machines STORE those partial votes, but I do know the Dominion machines are not REPORTING those fractions, if they are stored that way at all (they probably are).

{kind=link}
Assuming this is the data from the NYT election scrap data (which I am 99% sure it is) it is a decimal because of how it was calculated. In other words, this was an ANALYST error, not an error of the voting machines or reporting software. The scrap data was NOT the actual data. The actual data was from Edison. It was similar, but more accurate. The scrap data was only displayed to three decimal places. So same data, but less accurate. The scrap data was given in the format of:
Date, Total votes, .xxx, .yyy
where .xxx is the percent of of the total vote for Biden and .yyy is the percent of the total vote from Trump. Again, assuming this is the scrap data, the "# OF VOTES" column is (in this spreadsheet) calculated from the Total votes (current line minus previous lines of the Total votes column). It is because the data was only given to three decimal places (and because of how multiplication works) that all of the other columns are decimals. This has been an egregious oversight by many "analysts."
This error has given a lot of bad analyses. Even real mathematicians have made this mistake. Unfortunately mathematicians often don't work with actual data, and therein lies the problem. Don't get me wrong. There are PLENTY of REAL problems with the data that show it is not data from an election. I spent almost a month analyzing tons of election data and proved it was impossible, but this particular problem is analyst error, nothing more.
Why would any set of data regarding votes break one vote down into a decimal.
That's my point. The Edison data (the data that goes to the SOS of each state and is used to certify the elections) does not show that. The CALCULATION shows that.
Let me illustrate from a pretend entry from the NYT scrap data (again, the data set I believe this "analyst" used):
Date: 11/4/2020 12:00:00
Total Votes: 1,630,257
Biden Percent: .666
Trump Percent: .334
Other Percent: .000
Then, when you go to calculate the "Trump votes" and "Biden Votes" you get:
Biden Votes = 1,630,257 * 0.666 = 1,085,751.162
Trump Votes = 1.630,257 * 0.334 = 544,505.838
These calculations produce decimals (3 decimal point because that's how multiplication works). But that's not the real number being reported from the Dominion Servers to Edison (and presumably the SOS's).
The Edison data for such an entry would look something like:
Biden Vote: 1,086,129
Trump Vote: 544,128
These numbers not only don't have decimal places, but they aren't even the same number. The reason for this is one is reported (the Edison data) and the other is Calculated by multiplying a whole number (1,630,257) by a decimal accurate to the thousandths place (.666 e.g.).
The error value from such a calculation MUST be carried through or you get crappy analysis. In this case the real number from the Biden calculation is:
1,630,257 * 0.666 = 1,085,751.162 +/- 806.977
This means the REAL value for Biden falls somewhere between:
1,084,936.064 and 1,086,549.988 (which is confirmed in the Edison data).
This mistake was made by many people, not just the Jim Hoft, but he keeps running wild with it, making all kinds of false conclusions (like his "drop and roll" thing). Well, I shouldn't say his conclusions are all false, not all of them are. You don't need the increased precision from the Edison data to come to many of the conclusions, but a lot of his stuff is just plain wrong.
Again, the Edison data shows conclusively that it was NOT random samplings from a biased population (election data). In fact the Edison data shows it BETTER than the NYT .json scrap data.
I'm not buying it. There is no reason to ever have decimals as part of your calculations of votes. PERIOD. Just my opinion take it or leave it.
I am in complete agreement with your statement. What I am saying is, the data set that was used in this persons analysis (and MOST of the others that talk about "fractional data") are using the NYT scrap data set as their reference are not realizing THEY CREATED THE DECIMAL WHEN THEY DID THEIR CALCULATION.
The NYT .json scrap data was an incomplete data set. The NYT got their information from the Dominion (et al) servers, then when they got their NEXT piece of information, the previous piece got STORED in their .json database as a smaller amount of information (as I described above). This data had much less precision than the original.
I know its confusing. Many people succumbed to the exact same error, even good analysts. Even I did for a day or so, before I realized my mistake, and I've been working with large numerical data sets like this for twenty years.
I promise you: anyone who is getting decimals from the NYT data set is not "getting them" but calculating them themselves. The original (Edison) data set does not contain them.
That doesn't mean there are no places where there might be partial votes. The fact that you can calculate fractional votes in the Dominion machines themselves is a completely separate issue (e.g. we have seen real evidence that you can select a Biden vote to be worth 1.2 votes).
I don't know how the Dominion machines STORE those partial votes, but I do know the Dominion machines are not REPORTING those fractions, if they are stored that way at all (they probably are).